
A few weeks ago, I was reading some questions on Quora regarding the future of Home Computing. I gave some thoughts on the topic and provided some of the answers.
I would like now to extend my ideas to you, my readers, putting together all that I read and wrote in a nice essay. Please, keep in mind that these are my own thoughts, and I was not influenced in any way in writing them. Also, being my own thoughts, they are not necessarily in line with the current technology path. Maybe one day. Who knows…
Enjoy!
CPU architectures have started evolving in different directions than just increasing the number of transistors on the die to add new and powerful features. There are two reasons for that:
- They reached already some sort of physical limitation, in terms of minimum size of the transistors, which are quickly reaching an order of magnitude too close to the one of the atoms themselves for making transistors still work.
- The clock frequency being used limits the maximum distance between components to avoid incurring in huge delay in signal transportation that the CPU would not be able to handle without malfunctioning.

Matt Britt at the English language Wikipedia, CC BY-SA 3.0, https://commons.wikimedia.org/w/index.php?curid=5820383
The first reason makes it almost impossible to keep shrinking the size of the transistors on the die and, therefore, their quantity on the limited space of the chip.
The second reason prevents the CPU makers to increase the clock frequency any further without having to face major cost increases in the fabrication process. Of course, nobody wants to spend thousand of dollars on a single CPU, so they have already stopped, since a while, the race to increase the clock speed.
A common solutions to the two problems is already in place since a number of years now: rather than increasing the power of a single CPU and its clock speed, they decided to increase the number of less powerful CPUs on the same die. Or, better, I should say, they decided to duplicate the core functionality of the CPU, moving toward an architecture that, not without cause, has been named multi-core.
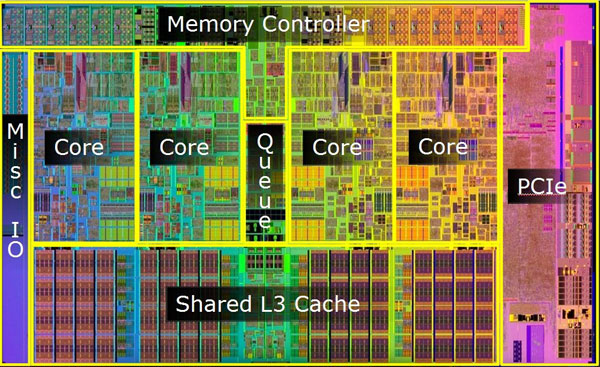
So, now, rather than executing more instructions per second by increasing the clock speed, they execute at a lower speed several instructions in parallel, one in each core, at least whenever it is possible. The result: an increase in performance without increasing the clock speed.
However, there is a catch! Several actually.
Increasing the clock speed allowed to increase proportionally the execution speed of the programs. But doubling the cores from one to two, does not double the execution speed. And that is because it is not always possible to execute two instructions in parallel on two different cores. Sometimes, you need to wait for the result of the previous instruction, before you can use it as an input to the next. Same goes when you increase the number of cores even more, to 4 or 6 or 8, and so forth.
Using multiple cores simultaneously becomes, therefore, more convenient for running different programs simultaneously, one per core. However, often a program running on a core needs to access the same external resources as another program on another core. And now, the contention needs to be solved. One of the two programs needs to wait for the other one. Ouch! Again, using the multiple cores this way does not multiply the efficiency of the CPU, because of these waiting times.
And so, here it comes yet another solution: hyper-threading. Why don’t assign two threads of two different programs to the same CPU core? So, when one thread needs to wait for an I/O operation, for example, the other thread can use the core to do something else that does not need the same resource.
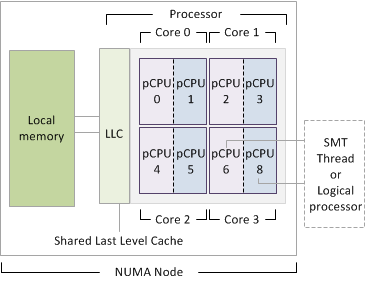
Nice, we got some more efficiency now, so an overall faster CPU. But, wait, what if the two programs on the two threads need to access the same resource at the same time? And here we are again, yet another bottleneck.
It seems like every time a new solution is put in place, it provides some enhancement to the previous status quo but, at one point, it ends up facing again the same obstacle, or maybe a new one. The fact is, that each and every of these enhancements, although it seems it could double the performance, it really does not, for one reason or another.
And, wait, there is more!
In order to really exploit the multicore architecture and the hyper-threading, programs need to be written in a new way. In the old days, you would write a program that executed in a structured way, making decisions whether to follow a logical path or another, along the way. New programs can better use the features of the new CPUs if they can be written in such a way that different operations are executed by different threads, so a program is, in reality, a collection of several smaller programs running in parallel.
And yes, we do that today, although not without difficulty. For example, since all the threads are still part of the same program, they sometimes need to access data that are generated or modified by another thread. And what happen if two or more threads need to access the same piece of data? How to figure out if a thread can read some data without taking the chance that it is reading garbage because, at the same time, another thread is modifying that data?
And here we go again: now the different threads of the same program need to compete for the same piece of data. So all the threads of the same program need to be coordinated, so to wait for one thread to finish with that piece of data before another thread can access it. And so new entities are introduced in programming languages, like the semaphore and the mutex. And so the programming languages have to evolve too, to keep the pace with the needs of the new generations of CPU.
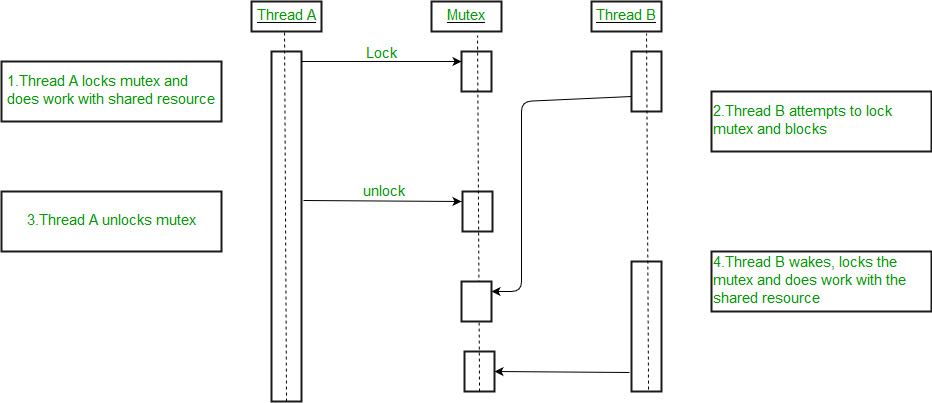
And, of course, the race has not ended. Every day we need more and more processing power, to have something able to process faster video frames, or to allow people to edit videos more smoothly. Or we need something to play video games with an amount of details that is greater every day.
So, what else can be done? Here is when we enter into the uncharted territories, the world of speculations, of fantasies. Who really knows what technology will bring us the future?
Optical CPU? Or, maybe, we just need to speed up those peripherals that are still slow when compared to the speeds of today CPUs?
And how do we do that? Well, one way is to make faster memory chips, to decrease the memory read/write waiting time. Another thing is to improve hard disk technology to make them respond fast to CPU requests. We are already abandoning the spinning plates of the HDD and embrace more and more a technology that has no moving parts, the SSD.

But, still, SSDs don’t seem to be the final answer to the problem. It is true they can achieve much faster speed when reading, but the writing part, although much better than that of the HDDs, still is definitively slower than the reading speed. And there are several reasons for that, some depending on the technology currently used for SSDs, and some depending on algorithms that attempt to use the SSDs in such a way that they can last longer.
So, do we expect yet another new technology that will emerge and will replace the SSDs? Probably. And there is promising research nowadays to do so, using optical systems without moving parts, or other ways to dope the silicon in a 3D fashion, rather than using 2D topology.
Maybe the future will also give us some sort of memory device fast enough to be used as main computer memory and also able to retain information when powered down, so it can be used also as mass storage device. What would you think of a type of memory chip that works seamlessly as main memory and main storage?
We just need to wait and see what the future has in store for us.
Let’s open a discussion on this topic. What are your thoughts? Any comments?


Leave a Reply